中国实体持股超15%红线,美国立法禁售奔驰过第一关

来源:汽车商业评论(李维)2023-12-05 15:38

回顾全球科技圈这一年最热的词和最热门的话题,ChatGPT和Open AI都是不可绕过的大神。
随着ChatGPT在技术、市场和眼球方面的一炮走红,Open AI的商业模式也在中国拷贝、复制。百度、华为、商汤等科技公司纷纷染指这一风口,中国迅速 掀起“百‘模’大战,它对正在兴起的汽车智能化以及智能座舱发展有何现实意义与实践?
在11月11日举行的2023中国汽车供应链峰会(CASCS)第二天议程上,出门问问大模型团队工程副总李维就大模型落地应用作主题演讲。他回顾过去一年大模型的发展,探讨了大模型的本性与痛点以及它在人工智能生成内容(AIGC)领域的前景。
谈及ChatGPT横空出世的意义,李维说“为什么说ChatGPT的发布标志着语言通天塔的正式建成?因为它把以前需要用样本才能交代的任务,改成了不需要样本,你直接跟它说话、下指令就可以了。”
李维指出,整个大模型的趋势叫AGI(通用人工智能),从OpenAI推动,最后就是边界越来越大,慢慢渗透到不同的领域,如果在车载领域当中,把车窗的交互和其他的人工智能的体验做上去,最后的护城河就是你的数据,因为你在别的方面没有办法跟真正的通用大模型的滚滚往前走的车轮比。
对于ChatGPT的能力和潜力,李维认为“没有任何问题”,但问题是有能力和能不能把能力变成钱,怎么能让它在商业上取得成功是两回事。
很多能力竞赛因为大厂的卷入,最终转换成免费的服务,或者转换成白菜价的服务,这个产业就被做死了。
对于未来的商业化,李维强调,总体而言,LLM落地应用的商业模式问题,其实没有根本解决。路在何方?还多在探索之中。
以下是李维的演讲实录,汽车商业评论记者张南、实习记者徐千麦整理,此处略有删节。

很高兴有机会跟大家谈一谈大模型以及大模型怎么落地的现状和前景。我做了一辈子自然语言处理,就是NLP,现在赶上了NLP大爆发(即大模型)的时代。
我的演讲分三个部分,先快速回顾一下过去一年大模型的风暴,然后探讨一下大模型本性和痛点,最后谈谈大模型在AIGC方面的现状和前景。AIGC的意思就是人工智能生成内容,这是大模型落地应用的重要方向。
多少年人类有这么一个梦想,如果建成语言通天塔的话,我们人类之间的交流就不再成为困难,人类在世界大同的路上就克服了一个根本的障碍。在《圣经》上语言通天塔叫作巴别塔。ChatGPT去年11月30日的发布,标志着巴别塔已经建成。这是划时代是事件。

为什么说巴别塔已经建成了呢?因为大模型实际上已经达到和超过人类的语言能力,事实上,它比我们 natives还native,无论是理解还是生成。不管你说的是一个顺畅的句子还是不顺畅的,也不管你说的是什么不同的语言,甚至方言,它都可以听得懂。生成能力更不用说了,写东西比我们要顺溜,文思泉涌。
我希望这次听讲的人,记住两个术语。它们特别重要,我想强调一下。一个是Few shots,一个是Zero Shot。什么意思?Few shots就是少量的样本,Zero Shot就是零样本,不给样本。
为什么说ChatGPT的发布标志着语言通天塔的正式建成?因为它把以前需要用few shots才能交代的任务,改成了zero shot,完全不需要样本,你直接跟它说话、下指令就可以了。
举个例子,以前你如果想让一个大模型在文本当中把里面的人名、地名或者是你感兴趣的任何类型的情报挖掘出来,你需要给它样本,让它举一反三。例如,告诉它我想抽取“张三”、“李四”这样的人名。你给它5个、10个样本以后,它就明白了,原来你要这样的东西,它有一个通过样本触发的泛化能力,它就可以把类似的人名抽取出来。
到了ChatGPT发布以后,你突然不需要给它样本了。你要人名,或者你要地名的话就直接说,请你把下面这篇文章的人名抽出来。这就是Zero Shot,不需要举样,它知道“人名”这个概念就是跟“张三”、“李四”这样的名字挂钩的。这是很大的突破。等于一下把门槛降到无限低,低到所有的人都可以跟它交流,给它发指令,语言和知识方面让它做什么事情都可以。模型听懂人话了。在这之前是半懂不懂,需要你 few shots给它举例。
回顾来看,few shots比此前已经很大进步了,在大模型时代之前要给机器学习成千上万的例子才可以做。前几天OpenAI开了 GPT Store的发布会,就更有神奇的色彩了。你喝着咖啡跟它聊着天,聊着聊着就可以给你造一个数字人,是满足你聊天中提出的要求的专职的数字人,而聊天用的都是自然语言,不需要任何代码。
我们回顾一下,11年前是第一次AI深度神经革命,在这之前是传统的人工智能,主流传统机器学习只能做专项的任务,局限性很强。
11年前做到什么呢?就是深度神经网络证明了,只要你给大量的标注样本,不是few shots,也不是zero Shot,我说的是大量的样本(thousands of shots),用大量训练样本告诉他想要做的事情,深度神经网络就可以做得跟人一样好,甚至比人还要好。爆发点在图像识别,后来也横扫语音和机器翻译,原因就是这些任务有很多标注样本,用样本就可以搞定,越多越好。
到了6年前,许多标注样本才能做的事情,没有办法了,因为遇到了自然语言文本的拦路虎。
自然语言里面你要做一个特殊任务,这些东西通常没有人类的标注。AI就遇到了这么一个瓶颈。怎么让人标注成千上万的样本,使得它知道我想要做的事情呢?你可以召集很多的民工,没完没了的标注,你可以做这件事情,但是只能做特定的任务,一旦换了另外一个任务,又要组织同样的力量才能把样本弄出来,这就成了知识瓶颈:没有办法对每一个自然语言任务,都有资源和时间去做海量标注。
但是,6年前大模型的出现就把这个瓶颈克服了。克服的根本原因是所谓自学习的东西被创造出来。自学习讲到底就是从语言学习语言,而语言文本无处不在,这样,样本就是无穷无尽的,学的是通用的能力,通用的语言能力后来证明可以赋能所有的自然语言任务。
大模型革命的原理就是如此。源源不断的原生自然语言是人类生活的自然副产品。突然被自监督学习巧妙利用 (用所谓“掩码”) 构成了训练大数据。每个人,包括死人,都成为自然标注员了,他们留下的数据共同成就了语言通天塔的建成。如果依赖刻意的组织性人类标注工作,再给50年,也难达到基础大模型现在表现出的功力。
时间推进到11个月前,不但是通用的语言能力和语言背后的知识被大模型学到了,任务需求变成Zero Shot了,大模型可以听懂人话指令了。
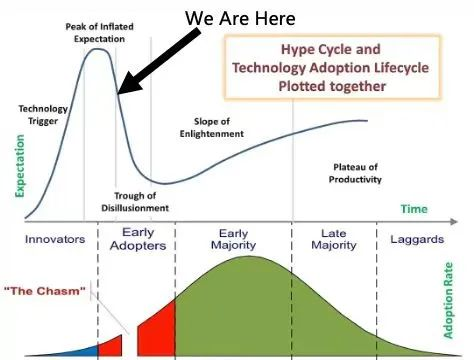
于是迎来了我们身处其中的信息产业的第三次大革命,丝毫不比前两次大革命逊色。第一次是互联网革命,第二次是移动平台革命。从宏观来说,这句话没有错,但是在我们这一行的人都知道我们现在实际上处于下滑期。这个下滑期也不奇怪,符合多次被验证的新技术的普及曲线(technology adoption curve):总结以前每次技术革命的爆发趋势,会发现当非常大的技术革命到来的时候,会一下子冲到顶,冲到顶以后会有一个下降期,我们现在处在下降期,现在还没有下到该触底的时候,触底反弹后就会比较健康平稳的发展。下滑是因为大模型落地应用遭遇了商业挑战。

现在不管是从大众媒体还是广播电视,你可以听到很多关于大模型的消息,一个浪潮高过一个浪潮,国内有百模大战,投入那么多资源进去,怎么说现在处于下滑期呢?
大模型是造出来了,美国先造出来,国内百模大战就跟着做,做出来的结果也不错,基本上复现了美国大模型的基础能力,表现在语言方面的能力,知识方面的能力,还有计算的能力和推理的能力等等。这些能力,中国的大模型都复现出来了,就这一点来说,我们赶超的劲头并不弱。人工智能就两家,一家叫美国,一家叫中国,其他的所有各家都远远落在后面。

但是实际上无论美国还是中国,我们都遇到一个大的问题,大模型是造出来了,但是我们不知道怎么用大模型赚钱,怎么为它找到一个能够持续的商业模式。
三个多月前,投资者就开始非常谨慎。我有很多投资圈的朋友,他们说从长期的趋势来说,大模型技术革命的整体浪潮大家都看到了,模型已经听懂人话,让它干什么就干什么,很多以前觉得不可思议的事情都可以办到。就是说,大模型表现出来的技术革命的潜力已经不是一个问题,这里有一个很大的共识。
但是具体到投资人,他们想的问题是在商业模式比较清晰之前,钱要烧多久才可以赚钱。总不能没完没了投,现在他们有冻结投资的意思。头部的一两家可能融资环境好一点,再往下其实很难,就是处于下滑期。
下滑期的原因是因为商业模式不清晰,不要说比较Web1了。Web1是互联网刚刚兴起的时候,主要商业模式就是基于在线广告的眼球经济,造就了Google,造就了亚马逊,造就的中国大厂还有百度、腾讯和阿里。
更近一点的技术革命就是mobile时代,造就的是美团、Uber和滴滴这样的超级应用。这些超级应用利用了mobile时代的特点,真正把买家和卖家连接起来了,然后平台可以收到规模效应。
现在,超级应用在大模型技术革命面前,我们还没有看到,我们不知道何时会出现,是怎样的产品形态。
大模型可以写个诗,写个文案,甚至你要过组织生活写报告,也比你写得快,写得好。现在写程序也有Copilot帮助你,编程序的效率显著提高。最近Open AI发布的GPT Builder使得一般的老百姓不需要懂得任何程序,也可以造一个“机器人”。
造什么机器人呢?我拿到GPT Builder 以后问自己。然后我就用自然语言跟它聊天,不编写任何程序,也造了一个机器人。我自言自语说我造一个机器人,帮助我做短视频。以前做短视频有一个问题,不管是GPT生成文案,或者自己写出文案,有了文案制成短视频,必须在短视频当中要加一些图,这是文生图的任务。文生图不是已经解决了吗?大模型是多模态了。但是要把文案作为输入,输出的是一连串的图,跟文字要对得上,这也不是特别简单的事情。我真的做出来了,花三个小时就做出来了。
我说希望你把文案首先按句子分开,如果一个句子太短就按两个句子来分,每分开一段,给我找一个最合适的图示。后来它就给我做,就是聊天聊着聊着就可以把以前需要一个工程师花一个星期都不一定做出来的东西,现在可以把它聊出来。简单得让人怀疑世界。
ChatGPT的能力大家能感受到,没有任何问题,但问题是有能力和能不能把能力变成钱,怎么能让它在商业上取得成功是两回事。有用的东西多呢,空气有用,水也有用,很多时候人并不会为空气和水买单。同样的能力,如果大厂卷入竞赛,你就发现可以把能力转换成一种免费的服务,或者转换成白菜价的服务,这个赛道就被做死了。商业被做死,就谈不上落地赚钱了。所以说,商业模式的问题其实没有真正解决。

我们再更深入地谈一谈大模型落地中到底有什么大的问题。
最大的问题就是幻觉问题,还有稳定性的问题,你确实是喝着咖啡聊着天就可以一天造好几个机器人出来,每个机器人都可以各司其职,完成你以前做不了的事情。但是你发现它常常不是百分之百的做好给定的工作,有时候也“阳奉阴违”,这个就很讨厌。

比如说我刚才做的那个机器人,我说你把这些生成的图放在文件里面,我就可以把文件下载,做短视频就更方便。我不愿意从屏幕上的输出结果一帧一帧的拷贝。在我的实验中,至少这个生成文件的指令它没听我的,稀里糊涂就上线了。当然,我还可以继续跟它唠叨,反复跟它唠叨,因为生成文件本身已经不是大模型的局限了。现在大模型的框架能力,调用一个函数也好,或者是输出什么格式以便调用数据库,或者把某些东西存成到一个local file,或者存成一个file给你一个链接等等,这些基本能力它都有。但是有这个能力并不意味着你让它做,它就百分之百按照你要求去做。这跟传统编程序不一样,编程序可能有bug不工作,但是把bug消除了以后,你让他做什么就做什么,这个百分之百有确定性的。
不稳定是因为随机性,随机性也是大模型的本性。大模型本来就是个概率模型,本身就有随机抽样在里面。这个问题在应用现场是很大的毛病:如果做一个实际的应用,你交付给客户,这个东西有时候work,有时候不work,有时候生成这样的结果,有时候生成那样的结果。客户是不能接受的。
还有个知识欠缺的问题。大模型本身是有很多知识的,知识特别渊博。但是它到一个具体垂直行业,知识是有限的,这可以理解,垂直行业的数据它可能够不着,有些是私有化的数据。垂直行业很多知识,比如说在一个场景当中,一个巨大的数据库里面有那么多具体的知识点,在序列学习所需要的大数据里面,很少有提到,或者干脆就不出现,没有人把所有的数据库知识点都变成自然语言读出来。
大模型本质上是概率模型。如果你要的知识在自然语言中没有冗余性,大模型是学不会的,它记不住,没有冗余性的知识在大模型训练中等同于噪音。

大模型落地的产品形态,其中最重要的两个概念是CoPilot(副驾驶),和Agent(智能代理)。CoPilot的意思就是作为助手的大模型给你用,大模型只是产生candidates,最终的采纳在用户或专家手中。这种形态下的大模型应用没有问题,因为幻觉可以由用户来纠正。其实,人最难的是做一件事情的过程,那个过程很痛苦,做出来以后,怎么挑错,人很能干,错了就改呗,所以幻觉不是问题,稳定性也不是问题。稳定性差就多生成一些候选,最后从候选中选优,拍板交付出去的是用户,这种是CoPilot的工作方式。大模型卷来卷去大多围绕着CoPilot的应用,同质化也很厉害,做的东西大同小异,反正都说是副驾驶。

副驾驶向前发展,逐渐就到智能代理的形态。智能代理有一定的“自主性”,你不需要告诉它“怎么”做,只需要告诉它目标是什么,有点像自动驾驶当中的L1/L2级的副驾驶,到L3/L4级的智能代理的跳跃。马斯克做自动驾驶,希望CoPilot越来越不需要人的时候,就自然演变成Agent,就能自主驾驶了。
最后说一下大模型商业落地的赛道。一个是副驾驶形态针对终端消费者的ToC赛道,基本上是赢者通吃,我们初创公司没有办法跟大厂比拼,应该主动回避。针对企业的ToB很难避免项目制模式。ToB的领域很纵深,常要求私有化部署,costs很大,也很难做。
像我们这样的公司的最新主张强调做ToPC(To Professional Consumer),对象是内容创作者,能够直接产生商业价值的地方。我们的AIGC配音产品魔音工坊,现在有40万的注册付费用户,说明有人买单。大模型真地提高了用户的内容创造能力,它可以收获更多的广告分成,自然也就愿意买单。