
卓驭科技欧洲总部正式开业,中国智驾出海正当时

来源:汽车商业评论(周洲)2024-04-22 10:00

特斯拉祸不单行。一边全球大裁员,一边经历“黑色星期五”。
4月19日,美股AI概念股们迎来了惨烈的“黑色星期五”。
英伟达暴跌10%,每股跌近85美元,创2020年3月16日以来最大单日跌幅,刷新历史最大单日跌幅纪录。竞争对手AMD大跌5.4%,芯片设计公司Arm跌近17%,晶圆代工龙头台积电稍微好一点,跌超3%。
作为上述芯片供应商的客户,特斯拉也未能幸免,本周跌幅居首,大跌超过14%,市值在4月15日一天就蒸发304.33亿美元(约合人民币超2200亿元)。
瑞穗证券驻场分析师乔丹·克莱因(Jordan Klein)表示,芯片领域“整个行业出现回撤”,过去一周左右时间里,回撤速度一天比一天快。
这对于正在加码AI的特斯拉来说是个雪上加霜的坏消息。
2023年9月,摩根士丹利还曾预判,特斯拉用于训练自动驾驶汽车人工智能模型的超级计算机Dojo可能会给这家电动汽车制造商带来“不对称优势”,使其市值增加近6000亿美元。
自2022年年底开始,AI 应用全面爆发、势不可挡,如今却遭到机构对AI投资热潮回调。特斯拉重金投入的Dojo超级计算机项目芯片研发进展不理想,在无法All in的现实中,马斯克聪明地作了两手准备:储备了足够多的仅次于扎克伯格Meta的英伟达芯片。
一位业内人士对汽车商业评论称,从一开始就对马斯克自研芯片不太看好。
“Dojo所用的是一种用于大模型训练的服务器芯片,与在汽车上运行的软件不同。其次,它(特斯拉)还没有准备好,制造芯片很不容易,需要时间积淀。我觉得像其他人一样购买现成的芯片是最好的路径。”这位人士称。
特斯拉在2021年的“人工智能日”(AI Day)上发布了Dojo,公布了自研芯片D1。

这是特斯拉用于云端训练AI模型的超级计算机,名字来源于日语,寓意为“道场”,象征着它是作为训练AI的地方。
Dojo旨在成为世界上最快的计算机之一,能够处理海量的视频数据,从而加速特斯拉Autopilot和全自动驾驶系统(FSD)的学习和改进,也为特斯拉的人形机器人Optimus提供计算支持。
Dojo的核心是特斯拉自主设计制造的神经网络训练芯片D1以及基于该芯片构建的训练模块、系统托盘和ExaPOD集群。
D1芯片采用台积电7纳米工艺制造,这款芯片集成了500亿个晶体管,并拥有354个训练节点,每个节点都包含一个处理器核心、一个高速缓存、一个高带宽内存和一个高速互连。D1芯片的峰值算力高达362TFLOPS,带宽达到36 TB/s。
为了进一步提高算力,特斯拉将25颗D1芯片进行无缝连接,形成一个训练模块。每个训练模块的峰值算力可达9PFLOPS,带宽为900GB/s。
这些训练模块构建了一个高密度、高性能、高可靠的系统托盘,每个托盘可容纳10个训练模块,并配备相应的电源、冷却和网络设备。每个系统托盘的峰值算力达到90 PFLOPS,带宽为9 TB/s。
最后,基于系统托盘,特斯拉构建了一个ExaPOD集群。每个集群由10个系统托盘组成,安装在一个机柜中。一个ExaPOD机柜模型的峰值算力高达900 PFLOPS,带宽为90 TB/s。
作为Dojo落地形式的ExaPOD,由3000片D1芯片构成,单精度算力为1.1EFlops。

根据特斯拉的公开资料,Dojo基于特斯拉自研D1芯片,用于替代基于英伟达A100的数据中心。截至2022年9月,该数据中心有1.4万片A100,是全球第七大数据中心。
特斯拉计划2023财年大概出货4万-5万片D1,2023年7月第一个ExaPOD已经投入运营,且预计在短期内向Palo Alto数据中心投入6个ExaPOD,算力共7.7EFlops。到今年四季度,Dojo算力目标是达到100EFlops(约91个集群)。
在2023年7月下旬的二季度电话会议中,马斯克表示没必要自造芯片,“如果英伟达能夠给我们足够的GPU,也许我们就不需要Dojo,但他们无法满足我们的需求。”
在自研的重要节点上,2023年11月,负责Dojo超算项目的负责人、同时也是特斯拉自动驾驶硬件高级总监加内什·文卡塔拉马南(Ganesh Venkataramanan)离职,职位由前苹果高管彼得·班农(Peter Bannon)负责。彼时有消息称,很可能是因为Dojo第二代芯片未达标,加内什遭到解雇。
加内什此前负责特斯拉Dojo超算项目已达5年,在进入特斯拉之前,他曾在美国知名半导体公司AMD任职近15年。
加内什的离职,被认为是特斯拉自研芯片不力,或者没有设想中那么顺利。
对马斯克来说,他能采取的措施就是一边想办法自研,一边购买合适的芯片。

一位网名为 “whydoesthisitch”的深度学习科研人员研究AI芯片已久,他解析了马斯克的Dojo无法依靠自研芯片的原因。
他认为,Dojo 仍可能处于相对早期的开发阶段,即使它加紧追赶,在性能方面仍将落后英伟达4 年以上。
今年3月20日,英伟达投下了Blackwell B200 炸弹,这是下一代数据中心和 AI GPU,将使得计算能力获得巨大的代际飞跃。
Blackwell 包含三个部分:B100、B200 和 Grace-Blackwell 超级芯片 (GB200)。
新的 B200 GPU 拥有 2080 亿个晶体管,可提供高达 20petaFlops 的 FP4 算力;GB200 将两个 GPU 和一个 Grace CPU 结合在一起,可为 LLM 推理工作负载提供 30 倍的性能,同时还能大大提高效率。
英伟达表示,与 H100 相比,它的成本和能耗“最多可降低 25 倍”。训练一个 1.8 万亿个参数的模型以前需要 8000 个 Hopper GPU 和 15 兆瓦的电力,如今,2000 个 Blackwell GPU 就能完成这项工作,耗电量仅为 4 兆瓦。
在具有 1750 亿个参数的 GPT-3 LLM 基准测试中,GB200 的性能是 H100 的 7 倍,英伟达称其训练速度是 H100 的 4 倍。
“而特斯拉确实夸大了芯片本身以及它们的开发进展,”“whydoesthisitch”认为,例如,特斯拉宣传 Dojo 突破了 exaflop 算力、Dojo跻身世界上最强大的计算中心之列之时,谷歌在俄克拉荷马州梅斯县的数据中心已经安装 8 个 TPUv4 系统Pods,该数据中心正在以接近 9 exaflops的总计算能力供谷歌云部门使用;亚马逊的AWS 使用 Trainium 芯片算力达到6 exaflops ,使用英伟达的 H100 GPU 算力达到 20 exaflops。
他认为,如果Dojo足够便宜,那它有理由取代英伟达。问题是,特斯拉的运营规模支撑不了这种庞大的研发投资。
今年1月16日,最近离职的特斯拉公共政策和业务发展副总裁的罗汉·帕特尔(Rohan Patel)在社交媒体X上发布了一则消息,称“周五晚上与埃隆·马斯克就一项大型AI数据中心投资进行了反复讨论。他决定批准这几个月来一直密切跟踪的计划。很难想到一位首席执行官比你能想象地更多地参与公司最重要的细节。”
资深科技博主汉斯·尼尔森(Hans Nelson)研究马斯克和特斯拉多年,他在随后的连线时评上称,Dojo肯定是大型AI数据中心的重要部分,但是帕特尔的这则推文却没有提及Dojo,估计是Dojo的芯片项目有点落后于他们希望推进的程度,这可能表示Dojo在短期内将更多使用英伟达的芯片。
Dojo原打算到今年2月,算力规模进入全球前五,今年10月算力总规模将达到100 exaflops,相当于30万块英伟达A100的算力总和。
尼尔森认为,Dojo目前算力能达到33exaflops,至于如何在10月达到100exaflops,以及目前的算力中使用的自研芯片和英伟达芯片各自占比,则无从得知。但可以肯定的是,无论Dojo是否能按照时间表实现算力目标,马斯克囤积了足够的H100GPU。
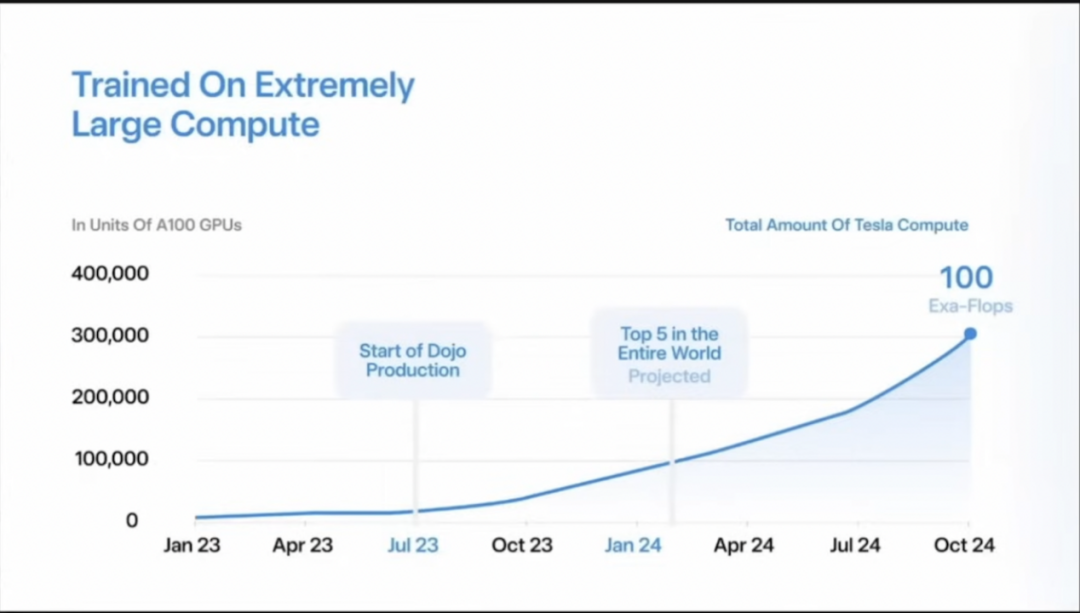
(图源:来自汉斯·尼尔森连线对谈视频截图)
H100GPU性能比此前的A100更好,特别是在AI训练和推理方面。H100基于英伟达Hopper架构,是第一代支持AI和HPC的Ampere架构的下一代架构,而A100是基于Ampere架构的产品。
10天后的1月26日,纽约州州长凯西·霍楚(Kathy Hochul)称,特斯拉将投资5亿美元,在该州的布法罗市(Buffalo)建造一台Dojo超级计算机。
虽然霍楚在发布会上着重提到了5亿美元的投资规模,但是特斯拉在社交媒体X上却有意淡化了这一数字,并指出该公司在2024年,在英伟达硬件上的投资将超过这一金额。
5亿美元相当于约 1 万颗 H100 GPU。
4月8日,X 平台用户“The Technology Brother”发布的囤积英伟达H100GPU排行榜上,Meta以35 万块位居第一。
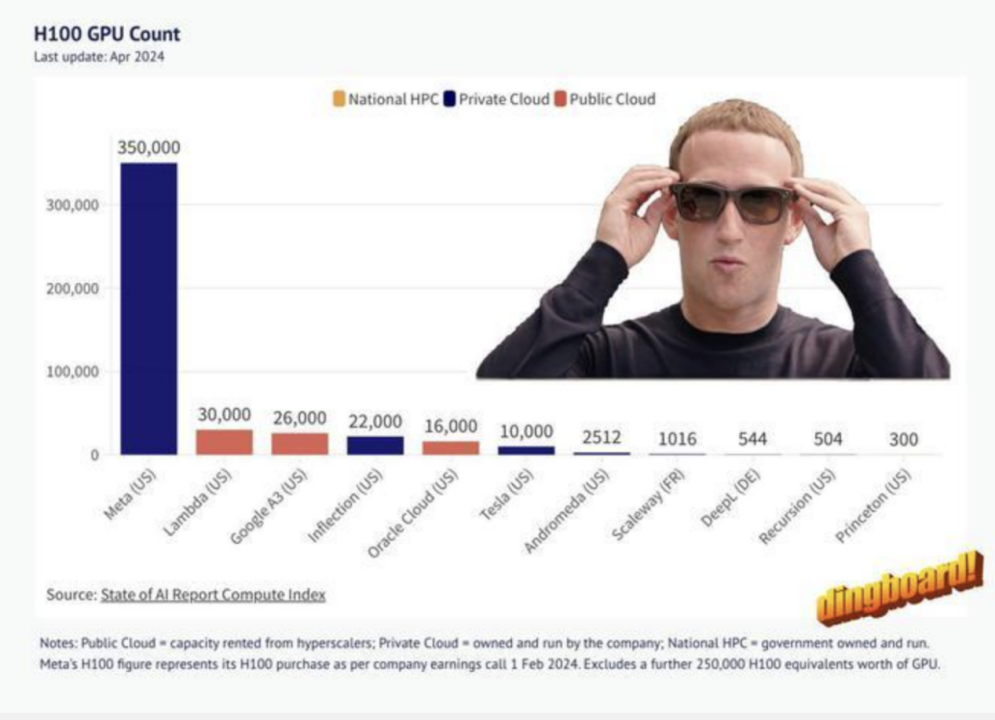
马斯克对该排行榜将特斯拉和 xAI 1万块的排名表示不满,并指出“如果计算正确,特斯拉应该是第二名,xAI 将是第三名”。
这意味着特斯拉可能拥有 3 万到 35 万颗 H100 GPU,xAI 则可能拥有大约 2.6 万到 3 万颗。
一直和扎克伯格针锋相对的马斯克,在不服气的嘴炮中暴露了真实状况:至少现在,Dojo的自研芯片失败,全面转向英伟达。
马斯克称,在人工智能领域保持竞争力,每年至少需要投入数十亿美元,并将会扩大购买英伟达竞争对手AMD的产品。
但“whydoesthisitch”认为,Dojo的算力规模要达到100 exa flops,估计要延至2027-2028年,而那时主流的云服务商比如亚马逊的算力已经达到zettaflop级别。
他称,目前Dojo的芯片性能其实只能达到H100的10%-35%,当它追上H100时,英伟达已经在新一代的Blackwell 上奔跑很远。
尼尔森则认为,至少马斯克意识到了,购买芯片还是最划算的。



